
I remember my first job as data analyst was to use Microsoft SSIS, a GUI ETL tool. We had only one data source back then, which was plenty enough for the business use cases.
In today’s modern world, that often looks like a joke or a utopia. Even if you have a small business, you quickly end up with many different services and other places to consume, process, and analyze data.
You end up doing the most boring data engineering job: moving data.
How did we get into this situation?
Why can’t we have data in a single place?
There are multiple reasons for data team to move data from system A to a system B with little to no transformation. Let’s cover a few common tasks :
Getting data from a source is often steps from 0 to 1 for any analytics project
Pulling data from an API and putting it in an Object Storage or Data warehouse
Moving data from an operational OLTP database to an Object Storage/Data Warehouse
Moving data from the Data warehouse to Object storage
Moving data from Object storage to an operational OLTP database
Migration project from data service A to data service B
In these use cases, there are transformations but few “business” transformations. They often involve mostly changing the form and type of data rather than effective business logic. It’s mostly about data compatibility: structure & format.
Some examples :
Flattening some JSON data (coming from an API) into a columnar format for loading into a data warehouse
Transforming into a new file format, typed, efficient for query and consuming less storage (e.g CSV to Parquet)
At the very end, we put data into different systems for performance reasons (cost, query latency, usability with BI tools). We need to do this because while there is some standard in file format, it’s not widely adopted.
The emergence of standards in file format
File formats like Parquet and supercharged file format supporting ACID like Delta lake, Apache Iceberg or Apache Hudi help to move data easier.
Many cloud data warehouses have been putting effort into making these file formats work with their ecosystem. However, remember that all Data warehouse like Redshift, Snowflake or Big Query for instance have their internal file format, and using these open-source standards comes today at a tradeoff in terms of performance.
The true bottleneck
So why is moving data still so hard ? Aren’t these file formats enough to conquer the problem space?
It’s all come down to data compatibility and how data transit between place. File format is one piece of the puzzle, but what protocol do we use to move these? Let’s look at how most databases communicate with the outside world to transfer data, our old friend JDBC.
JDBC has been around since the mid-1990s (!), providing a vendor-neutral interface for accessing databases from Java applications. But as technology has evolved, JDBC has started to show its age. Of course, as you may know, it can also be used by other programming languages through JDBC drivers. These drivers bridge the JDBC API and the programming language, allowing other languages to use JDBC to interact with relational databases.
This makes it a versatile technology that can be integrated into different systems and used by multiple programming languages, not just Java. It’s a common standard today in the data ecosystem, especially for many BI tools.
Enter the saver from the shadow: Apache Arrow
Created in 2016, Apache Arrow is an open-source, in-memory data format and transport mechanism that provides a standardized, efficient, and interoperable solution for data processing and exchange across different platforms and programming languages.
Arrow aims to improve data transfer and processing performance by providing a columnar data format that enables better compression, vectorization, and SIMD parallelism. Apache Arrow has gained significant popularity in the data processing and analytics communities for these reasons.
Some primary reasons why it beat JDBC :
JDBC protocol uses a row-based data transfer approach, which can result in high network overhead and increased latency for large datasets.
JDBC may require multiple round trips between the client and server for data transfer, making it inefficient and slow compared to Apache Arrow’s optimized data transfer mechanisms.
Apache Arrow’s columnar data format allows for better compression, vectorization, and SIMD parallelism, resulting in significant performance improvements over JDBC’s row-based
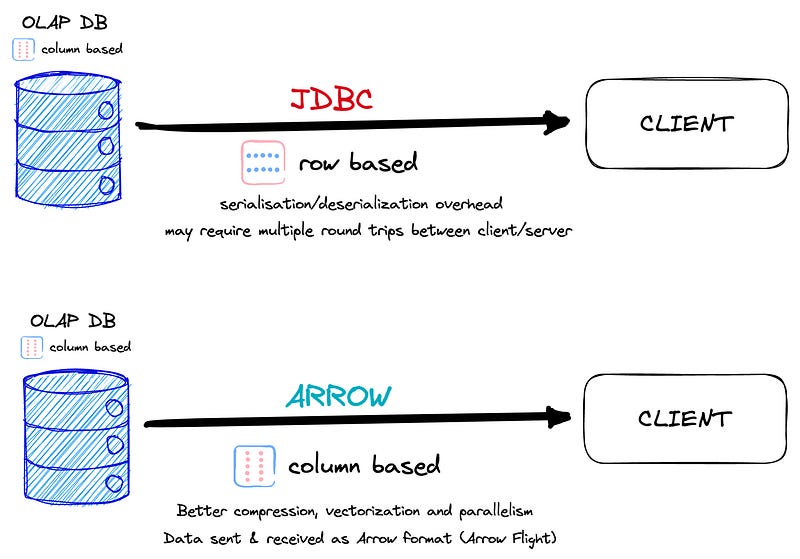
Column-based databases are the most common places where we consume analytics today, aka Cloud Data Warehouse (BigQuery, Snowflake, and Cie). And so are the file formats used today, like Apache Parquet, Delta Lake, and Apache Iceberg. Arrow is, therefore, in the right place to be used around these tools.
Practical Tips to get the most of Arrow 🏹
Consider implementing the following strategies:
Evaluate your existing data stack: Assess your current data stack to identify areas where Apache Arrow can be integrated to optimize data movement and processing. Determine which systems and tools are compatible with Arrow and can benefit from its columnar data format.
Embrace open-source columnar file formats: Use formats like Parquet, Delta Lake, Apache Hudi or Apache Iceberg to enable better data compatibility and interoperability.
Leverage modern data tools: Choose modern data tools that support Apache Arrow, such as Polars, DuckDB, Apache Flink or Apache Spark to take advantage of its performance benefits.
Stay informed about new developments: Keep an eye on Apache Arrow’s ongoing developments and improvements and its growing adoption in the data community.
What the future looks like?
The future of database protocol is looking brighter than ever! While using a standard file format does have some performance tradeoffs, Arrow’s role in properly interfacing data has huge potential.
With its growing adoption, Arrow is expected to simplify moving data between different systems, minimizing the need for extra serialization and deserialization. Its columnar format makes data transfer efficient, and its support for multiple programming languages and platforms makes it incredibly versatile.
Soon, you’ll be able to spend less time on the mundane task of moving data and more time generating valuable insights for your business.
To quote Tristan, CEO at dbt labs during an interview I did last October, “I want Apache Arrow to take over the world.”
In the meantime, may the data be with you.