🧠 AI is inflating numbers
I was browsing skills repos and realized a SINGLE CLAUDE.md of 65 lines “from karpathy” pulled 155k GitHub stars in a few months 🤯. Something even more crazy : it isn’t actually from Karpathy. It’s just a tweet of his on LLM coding pitfalls turned into a skill and dropped into a repo.
GitHub stars were always a vanity metric, but they still meant something. With AI in the loop, that signal is mostly noise now.
And it’s not just stars. Downloads, views, you name it. I keep hearing the same thing about startup metrics: two person companies posting absurd ARR and raising at speeds we have never seen, in a matter of MONTHS.
Don’t get me wrong, I’m not saying AI is going to magically make us move faster as a saviour. I’m just noticing that our usual metrics are shifting, so be aware to adapt your mindset!
🧠 Token bills are breaking budgets
Gergely Orosz dropped some sobering numbers on AI token spending. Teams are hitting five-figure monthly bills, often from a single dev firing off the most expensive models for everything.
The pattern is always the same: “just try it” -> someone generates documentation for $3000 -> suddenly everyone wants cost controls. I’ve seen this at multiple companies now. The smart teams set budgets upfront and route low complexity tasks to cheaper models by default.
Funny tension though: the public talking point from the Nvidia CEO and the Lovable CEO is basically that you SHOULD be burning more tokens, not fewer (ok, they are selling AI, fair point). Probably not what your CFO wants to hear.
If you want to have better visbility on your spending on macOS, I just started to use codexbar :
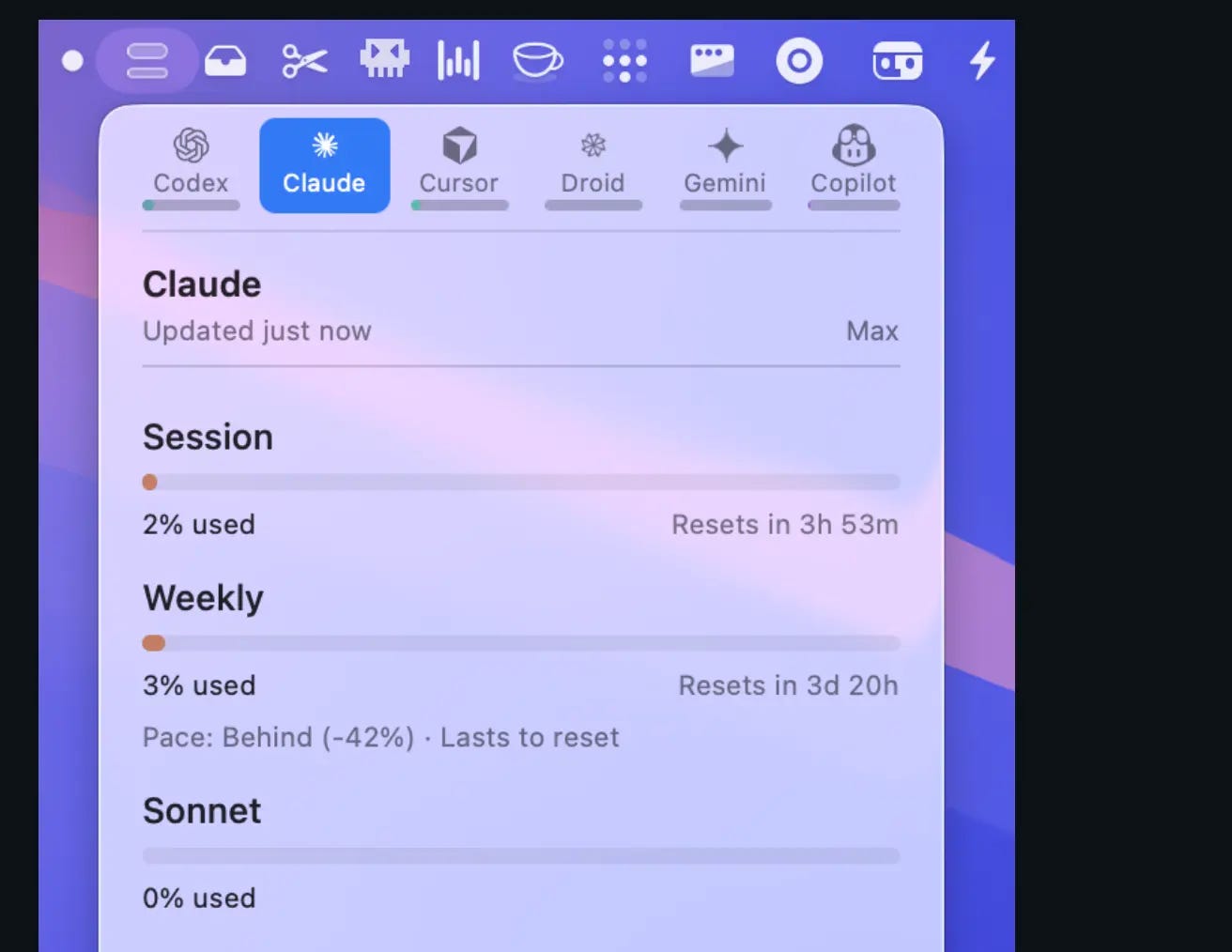
Hard to over-spend when you watch the meter tick.
🛠️ Codex inside Claude
OpenAI’s latest models have seriously caught up with Opus 4.7. The fun new thing is mixing them: Codex for one part of a refactor, Claude for another. I’ve found this really useful when designing complex apps from scratch or doing larger refactors where one model alone starts to drift.
That being said, every lab is locking down its ecosystem. They want you on their subscription, not raw API, which makes switching tools more annoying than it used to be. A few open standards still survive (Claude skills being one), and OpenAI dropped a small trojan horse (figure of speech, not an actual virus 🙈) in the form of a Claude skill that calls Codex for code review.
Here is Claude’s reaction to one of Codex’s reviews. At least they are still polite with each other, for now...
Good review, all seven points are real fixes. Let me fold them into the plan.🛠️ Obsidian opens up the plugin store
The folks at Obsidian (best note taking app ever, plain markdown, fight me) just changed how community plugins get approved. AI has been so empowering that they were getting roughly one new plugin PR every four hours 😱. They couldn’t keep up, and submitting a plugin felt like shouting into a void.
Now there is automated approval and a proper community store.
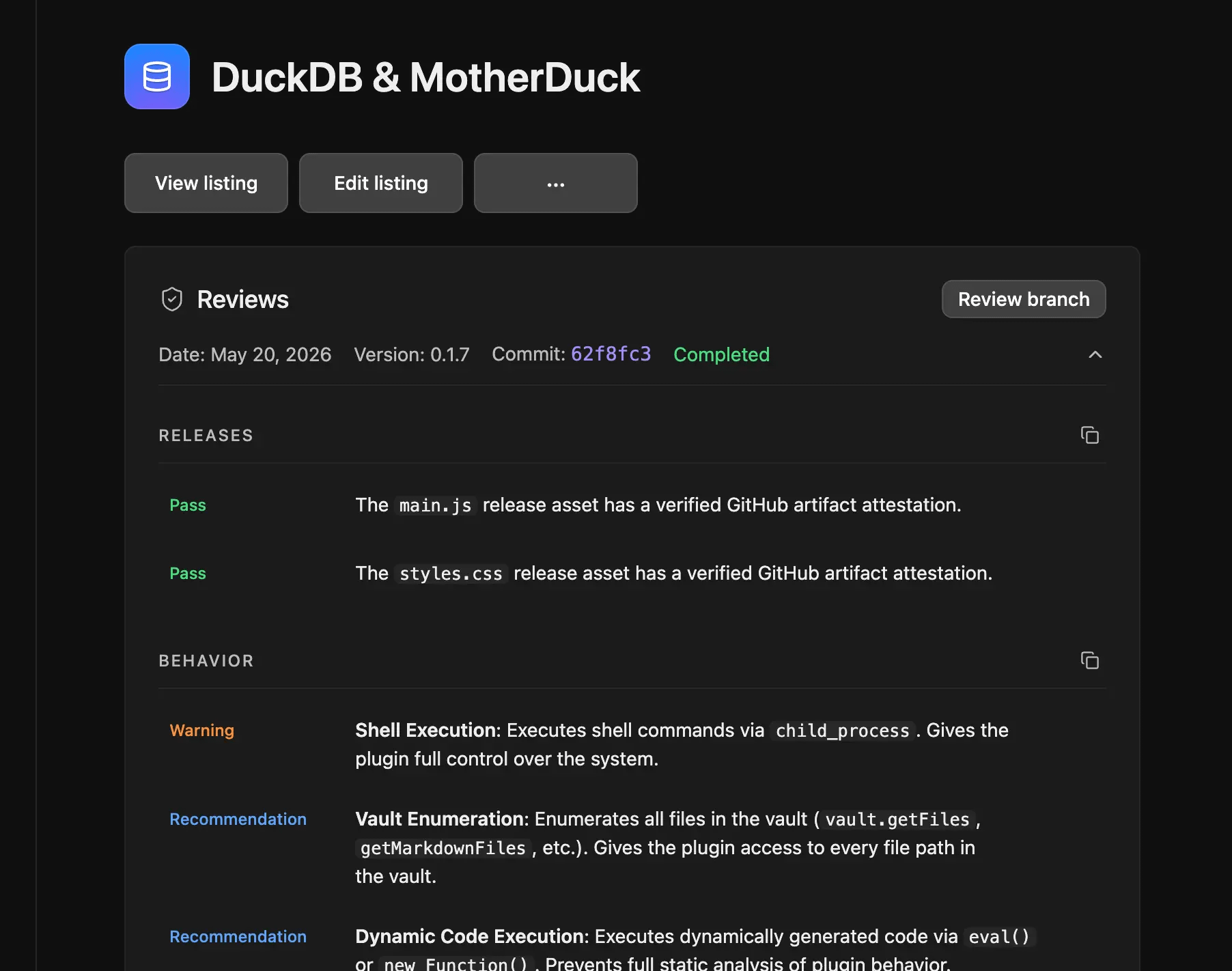
I had a really nice experience going through this with the DuckDB + MotherDuck Obsidian plugin. Yes, shame plug for my new plugin : you can cache SQL results inside your markdown notes, and even trigger queries through an agent thanks to the Obsidian CLI 😎.
🛠️ SentrySearch: video search that actually works
SentrySearch lets you search videos with text queries or screenshots. Ask “show me code examples” or upload a frame to find similar moments.
Under the hood it chunks videos, generates embeddings with Gemini or Qwen3-VL, and builds a searchable index. Works locally or with cloud APIs.
Video search is one of those big unsolved problems. So much specific learning is stuck inside videos (or transcripts at best). The other big use case is editing, where half the work is just gathering footage and finding the right clip fast.
Been wanting something exactly like this for my personal library. Will report back on how well it actually works.
📚 What I read / watched
“When using AI leads to brain fry”, HBR: the formal version of the Vicki tweet above. Cognitive offload has costs we are only starting to measure. A lot of nice replies.
“How agents use systems differently” by Davis Treybig: agents poke at our software in weird ways, and most products were not built for that traffic shape.
“The unreasonable effectiveness of HTML”: tokens are 2 to 4x more expensive than they should be because we keep mixing content and presentation. Worth a think.
Max Schoening on Lenny’s Podcast on Notion, agency, and malleable software: apps today are locked squares, fully DIY is exhausting, the middle ground is platforms that let users tweak and share without rebuilding from scratch.
“An AI state of the union: we’ve passed the inflection point” with Simon Willison on Lenny’s Podcast: “Using coding agents well is taking every inch of my 25 years of experience.”
“Vibe coding is killing OSS”: as AI gets better at generating code, contributions back to the upstream libraries drop. Who maintains the stack when everyone is just prompting?
That’s it for this week. The AI reality check continues. Meanwhile, nothing beats handwriting on your hand to detect allergy
